
前言
好吧,又是好久没有更新正儿八经的博客文了,可能是因为期末的原因,在这里再次道歉
说回正题,这次就主要讲讲很麻烦(至少对我而言是这样的)的东西——DP,也就是动态规划
这个对于大部分新手而言(当然,天赋型选手除外)都是比较难以理解的一种算法思想,所以我会在这里尽量以通俗的方式进行讲解
顺带也会讲讲一个非常典的背包问题,当然,在这里只涉及01背包和完全背包,而至于多重背包,这玩意太难而且在算法方面并不是很重要,所以我不打算展开讲了(如有兴趣可以自己查)
当然我会在背包问题上顺便讲解一些暴力算法是怎么做的,以及DP后是怎么做的
好了,差不多了,也该讲正题了
DP(动态规划)
定义
DP(动态规划),本质上是一类算法设计思想
在维基百科里,他的具体定义是这样的(链接:动态规划 - 维基百科,自由的百科全书):
动态规划(英語:Dynamic programming,简称DP)是一种在数学、管理科学、计算机科学、经济学和生物信息学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
动态规划常常适用于有重叠子问题和最优子结构性质的问题,动态规划方法所耗时间往往远少于朴素解法。
动态规划背后的基本思想非常简单。大致上,若要解一个给定问题,我们需要解其不同部分(即子问题),再根据子问题的解以得出原问题的解。
通常许多子问题非常相似,为此动态规划法试图仅仅解决每个子问题一次,从而减少计算量:一旦某个给定子问题的解已经算出,则将其记忆化存储,以便下次需要同一个子问题解之时直接查表。这种做法在重复子问题的数目关于输入的规模呈指數增長时特别有用。
当然,
总而言之,是通过把原问题分解为相对简单的子问题的方式求解复杂问题的一种方法
以上定义很抽象,不好理解
简单来讲,DP的核心思想就是:
拆分子问题
记住已经解过的结果
减少重复计算
当然,在这里也可以用一种非常典型的话来讲,就是:“以空间换时间”
虽然有些DP会为了使用维度更低的数组等方式来减少空间容量,不过基本都是这样子的
举个简单的例子:一个人在写数学题,如果不用DP,就相当于硬着从头开始写,而有了DP,就类似于拥有了草稿纸,我们可以通过草稿纸直接用引用已经得到的结果
毕竟DP本身是一大类算法,肯定会有人会提到递推DP和记忆化搜索这玩意,于是这里简单提及俩句:
递推DP和记忆化搜索的区别
递推DP和记忆化搜索本质上是同一个DP实现的,本质上记忆化搜索就是递归DP,当然,俩种用法有一定的区别:
一、首先,很显然,递推DP用的是递推,而记忆化搜索用的是递归
二、递推DP是自底向上的递推方式,从最小子问题开始依次计算并保存结果,而记忆化搜索采用自顶向下的递归方式,从原问题出发,在需要时递归求解子问题,并通过缓存避免重复计算
三、俩者的空间复杂度大都相同,但记忆化搜索通常会占用更大的空间
简单示例
这里用一道洛谷上的题来简单演示下吧:
原题:
P1002 [NOIP 2002 普及组] 过河卒 - 洛谷
不想去原链接看的可以看这里
题目描述
棋盘上 A 点有一个过河卒,需要走到目标 B 点。卒行走的规则:可以向下、或者向右。同时在棋盘上 C 点有一个对方的马,该马所在的点和所有跳跃一步可达的点称为对方马的控制点。因此称之为“马拦过河卒”。
棋盘用坐标表示,A 点 (0,0)、B 点 (n,m),同样马的位置坐标是需要给出的。
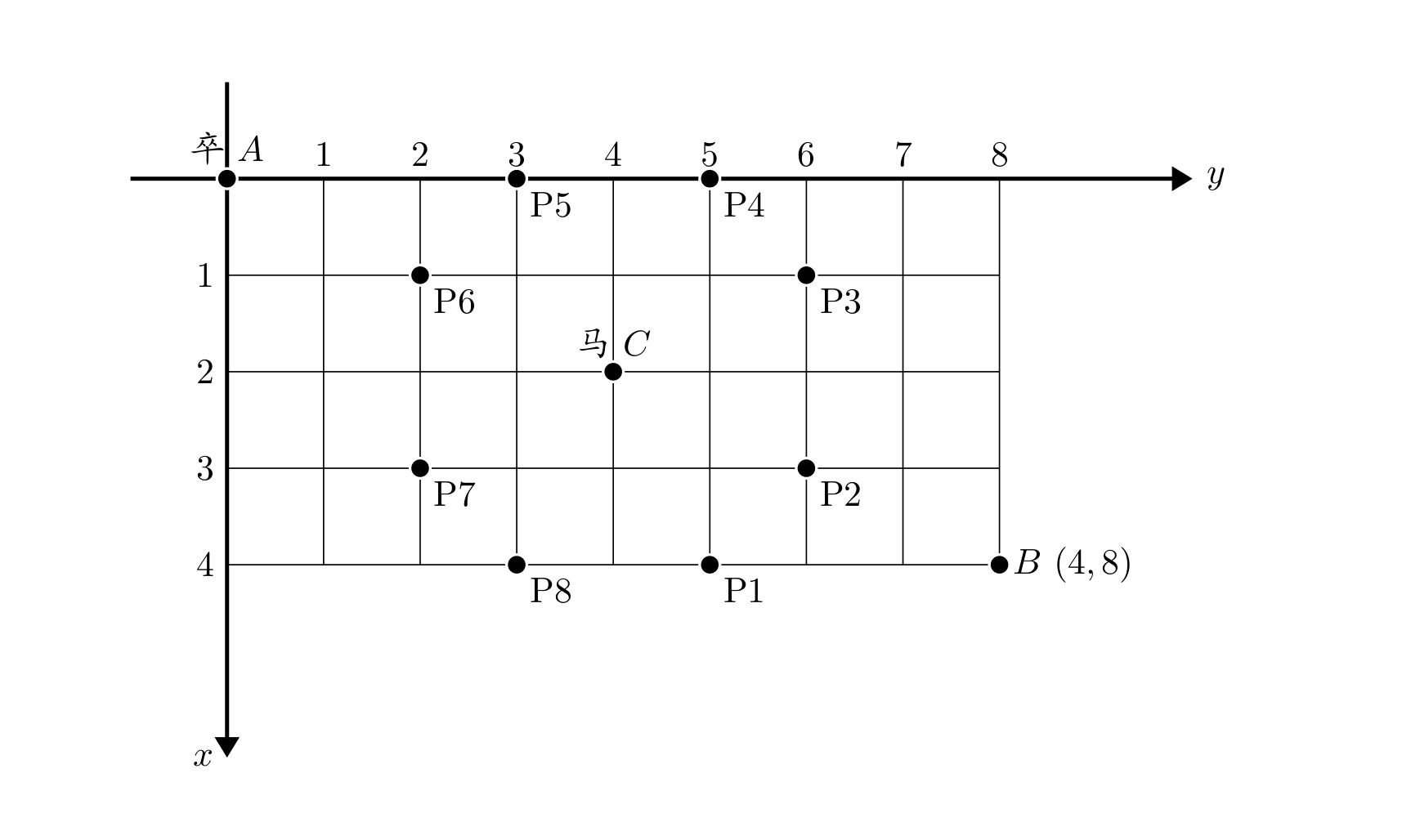
现在要求你计算出卒从 A 点能够到达 B 点的路径的条数,假设马的位置是固定不动的,并不是卒走一步马走一步。
输入格式
一行四个正整数,分别表示 B 点坐标和马的坐标。
输出格式
一个整数,表示所有的路径条数。
输入输出样例
输入 #1复制
6 6 3 3
输出 #1复制
6
说明/提示
对于 100% 的数据,1≤n,m≤20,0≤ 马的坐标 ≤20。
【题目来源】
NOIP 2002 普及组第四题
这里笔者看到这题,第一反应是拿DFS跟他爆了(当然不知道DFS请先看看这个链接:DFS和BFS|真理の小屋),于是使用了以下代码(这里为了方便演示,优化了变量名,请见谅):
def dfs(x,y):
global result
if x==bx and y==by: #如果到达了B点
result+=1 #方案数+1
return
elif x>bx or y>by or (x,y) in Horse: #如果超出的界限或者被马“吃了”
return #直接return
dfs(x+1,y) #向右
dfs(x,y+1) #向下
bx,by,hx,hy=map(int,input().split())#bx,by代表B点,hx,hy代表马的位置
Horse=[(hx-1,hy-2),(hx-1,hy+2),
(hx+1,hy-2),(hx+1,hy+2),
(hx-2,hy-1),(hx-2,hy+1),
(hx+2,hy-1),(hx+2,hy+1),
(hx,hy)]
#以上是马的八个方向
result=0#方案数
dfs(0,0)#使用dfs
print(result)#输出方案数当然,在自信写出来之后,直接:
于是,后面进行了一定的学习,发现直接用DFS跟他爆是会出现计算多余的,换言之,就是需要动态规划这玩意进行记忆存储,来减少纯DFS那多余的计算量(换言之,就是用到前文所提到的记忆化搜索):
def dfs_dp(x,y):
global result
if (x,y) in m: #如果这个点已经走过了
return m[(x,y)] #返回已经做过的数
if x==bx and y==by: #如果到达了B点
return 1 #返回1
elif x>bx or y>by or (x,y) in Horse: #如果超出的界限或者被马“吃了”
return 0 #返回0
result=dfs_dp(x+1,y)+dfs_dp(x,y+1) #经典的DFS部分
m[(x,y)]=result #存储当前的方案数
return result #返回方案数
bx,by,hx,hy=map(int,input().split())#bx,by代表B点,hx,hy代表马的位置
Horse=[(hx-1,hy-2),(hx-1,hy+2),
(hx+1,hy-2),(hx+1,hy+2),
(hx-2,hy-1),(hx-2,hy+1),
(hx+2,hy-1),(hx+2,hy+1),
(hx,hy)]
#以上是马的八个方向
result=0#方案数
m={} #DP核心,这里使用字典来存储,也可使用二维列表来存储,但二维列表容易MLE
print(dfs_dp(0,0))#使用dfs_dp方法,并直接输出AC力:

这里可能有人会看我这么讲,不知道俩种方法的时间复杂度是多少,这里用表格表示了:
这里就演示的差不多了,可能有人在我讲解完之后,一下哦恍然大悟,结果一做直接死,于是这里就简单讲解下要注意的东西
注意
这里简单讲一下要注意的东西:
要明确问题,看题的时候需要看这玩意能不能用DP,或者说看看范围适不适合用DP,DP这玩意你想出来以及写出来其实是比暴力而言是要麻烦的(当然,平时刷题想玩最优解的另说),不能说你看到哪个就直接无脑上DP
避免重复计算,因为DP的意义本身就是通过存储来减少计算的,若使用,则会失去原本的意义
条件边界处理,这个其实放其他的算法也是差不多的,只不过放到DP上,你不限制DP里的容器是很容易出现问题的
需要优化空间复杂度,这个不多说,毕竟DP本身是空间换取时间的算法,但你用的空间过多是超容易MLE的,不过得看情况区别对待,比如说实际访问较多的就推荐使用数组,实际访问较少用字典等
DP讲完了,接下来就是讲解非常经典的背包问题了:
背包问题
基本定义
背包问题么,简单来讲就是给一些带有重量和价值的物品,在背包容量有限的情况下,选定这些物品,使这些物品能够实现价值最大化的问题
在这里,问题一般可以分俩种:
背包不超过约束:在重量不超过背包容量的前提下(装的总重量≤背包容量),使装的总价值最高
背包必须装满约束:在固定的重量下(装的总重量=背包容量),装的总价值最高,若无法达成该条件,则明确输出“无解”或其他题目内等价的失败标识
在问题上分类可能不是太明确,但按照物品可被选择的次数上分类,可以分3种:
01背包问题:物品只能选一次或者不选
完全背包问题:物品可以选无数次
多重背包问题(这里不细讲):物品可以选有限次
当然,同样的,可能对于有些新人而言,我讲的会不太明确,于是我决定在这里放下维基百科的内容来作为辅助理解(原链接:背包问题 - 维基百科,自由的百科全书):
背包问题(英語:Knapsack problem)是一种组合优化的NP完全问题。问题可以描述为:给定一组物品,每种物品都有自己的重量和价格,在限定的总重量内,我们如何选择,才能使得物品的总价格最高。问题的名称来源于如何选择最合适的物品放置于给定背包中,背包的空间有限,但我们需要最大化背包内所装物品的价值。背包问题通常出现在资源分配中,决策者必须分别从一组不可分割的项目或任务中进行选择,而这些项目又有时间或预算的限制。
在定义上讲的差不多了,在接下来的背包问题的演示以及讲解之前,我先对此做好输入格式的统一说明,以便理解我接下来要干什么:
输入格式
输入格式大致为这样:
n bag
w1 v1
w2 v2
...
wn vn
输入格式已讲述完毕,接下来就是对背包问题中的01背包和完全背包进行带代码的演示以及讲解:
01背包
正如前文所提,01背包就是物品只能选一次或者不选,这个对于遍历所有情况的来说是比较轻松的,换言之如果范围小,就可以使用暴力来解决,以下便是俩种做法的区别与演示:
暴力做法
暴力算法么,就是很典型的遍历所有情况,找最好的情况,在这里,01背包可以用DFS来暴力破解:
def dfs(idx,value,weight):
global max_values
if weight > bag: #如果超重,直接剪掉
return
if idx==n: #如果idx到了n,如果是需要严格=背包重量的,if idx==n and weight==bag即可
max_values=max(value,max_values) #把value与max_values做比较
return
#遍历俩种情况
dfs(idx+1,value+items_v[idx],weight+items_w[idx])
dfs(idx+1,value,weight)
n,bag=map(int,input().split())#n为多少个物品,bag为背包容量
items_w=[]#放重量的数组
items_v=[]#放价值的数组
max_values=-1#最大价值
for i in range(n):
w,v=map(int,input().split()) #w代表重量,v代表价值
items_w.append(w) #w塞入数组
items_v.append(v) #v塞入数组
dfs(0,0,0)
print(max_values) #输出在这里,暴力解法我只做了一种情况,也就是不超过背包容量(装的总重量≤背包容量)的情况,若需要背包必须装满(装的总重量=背包容量)的情况,if idx==n and weight==bag即可
当然,暴力做法仅适用于量少的情况,完全比不上DP啊那些的,接下来就是DP做法:
DP做法
在此之前,我们要先了解在背包问题种DP数组的含义是什么,不能说一上来就用这个,然后认真去看发现自己其实对里面的代码尚未真正理解
这里面DP数组(这里讲二维数组版的)的含义大致为:在dp[i][j]中,下标[0,i]的物品任取放进容量为j的背包里的最大价值
DP的做法其实有俩个:一个用二维数组,一个用一维数组,在这里,我就简单对此做个演示吧:
二维数组版
这个二维数组版只要DP是什么就很容易明白这是在干什么了:
n,bag=map(int,input().split())#n为多少个物品,bag为背包容量
dp=[[0 for i in range(bag+1)] for j in range(n+1)]#dp数组
items_w=[]#放重量的数组
items_v=[]#放价值的数组
max_values=-1#最大价值
for i in range(n):
w,v=map(int,input().split()) #w代表重量,v代表价值
items_w.append(w) #w塞入数组
items_v.append(v) #v塞入数组
for i in range(1,n+1): #枚举物品
w=items_w[i-1] #获取第i-1的重量
v=items_v[i-1] #获取第i-1的价值
for j in range(bag+1): #枚举背包的容量
#如果当前物品重量不超过当前背包容量
if w<=j: #如果物品不超背包容量
dp[i][j]=max(dp[i-1][j],dp[i-1][j-w]+v) #选/不选
else:
dp[i][j]=dp[i-1][j] #继承上一行
print(dp[n][bag]) #输出顺带,如果是要背包必须装满的情况,则可以直接写成这样:
n,bag=map(int,input().split())#n为多少个物品,bag为背包容量
dp=[[-1 for i in range(bag+1)] for j in range(n+1)]#dp数组
dp[0][0]=0 #初始为0
items_w=[]#放重量的数组
items_v=[]#放价值的数组
max_values=-1#最大价值
for i in range(n):
w,v=map(int,input().split()) #w代表重量,v代表价值
items_w.append(w) #w塞入数组
items_v.append(v) #v塞入数组
for i in range(1,n+1): #枚举物品
w=items_w[i-1] #获取第i-1的重量
v=items_v[i-1] #获取第i-1的价值
for j in range(bag+1): #枚举背包的容量
#如果当前物品重量不超过当前背包容量
if w<=j and dp[i-1][j-w]!=-1: #如果物品不超背包容量且背包在容量j-w是可达的状态
dp[i][j]=max(dp[i-1][j],dp[i-1][j-w]+v) #选/不选
else:
dp[i][j]=dp[i-1][j] #继承上一行
print(dp[n][bag]) #输出一维数组版
这里,一维数组DP的作用是:在不同背包容量限制下,能够获得的最大总价值的
n,bag=map(int,input().split())#n为多少个物品,bag为背包容量
dp=[0 for i in range(bag+1)]#dp数组
items_w=[]#放重量的数组
items_v=[]#放价值的数组
max_values=-1#最大价值
for i in range(n):
w,v=map(int,input().split()) #w代表重量,v代表价值
items_w.append(w) #w塞入数组
items_v.append(v) #v塞入数组
for i in range(n): #依旧遍历每个物品
for j in range(bag,items_w[i]-1,-1): #依旧保证每个只能使用一次
dp[j]=max(dp[j],dp[j-items_w[i]]+items_v[i]) #依旧选和不选中做选择
print(dp[bag]) #输出这里就不演示背包必须装满的情况了,如果愿意写的话建议自己试着写一下
完全背包
完全背包就是不限制物品的数量了,前文在讲基本定义的时候讲过
在这里,我就不再演示暴力做法版本了(一来就算做了也是超时的,二来也没必要),直接上DP版本了:
具体做法(DP)
在这里,DP的作用跟01背包相似(毕竟01背包和完全背包同源),由于一维数组版与01背包极其相似,于是先直接放出代码了:
n,bag=map(int,input().split())#n为多少个物品,bag为背包容量
dp=[0 for i in range(bag+1)]#dp数组
items_w=[]#放重量的数组
items_v=[]#放价值的数组
max_values=-1#最大价值
for i in range(n):
w,v=map(int,input().split()) #w代表重量,v代表价值
items_w.append(w) #w塞入数组
items_v.append(v) #v塞入数组
for i in range(n): #依旧遍历每个物品
for j in range(items_w[i],bag+1): #正序让其能无限使用
dp[j]=max(dp[j],dp[j-items_w[i]]+items_v[i]) #依旧选和不选中做选择
print(dp[bag]) #输出至于为啥这个是正向遍历,因为完全背包是继承本层左侧状态的,当然同样的,这里也不做背包必须装满的情况了
总结
DP这玩意就是很典型的空间换时间的算法设计思想,同样的,背包问题也是同样典型的问题
至于在里面如何使用DP或者怎么用DP的,建议先看看我在DP中的注意部分之后再深入思考下,为什么要用
差不多写到这里了
